I am really excited to introduce BlobIt, a brand new distributed object storage.
A distributed object storage is a network service that allows you to store raw data (like files, but without a filesystem).
This kind of services do not need a shared medium like expensive shared arrays of disks, SAN...., but the system replicates data over several machines.
These machines usually are helds in several racks and a single cluster may span even more than one datacenter.
BlobIt is mostly an application layer on top of Apache BookKeeper which provides powerful primitives to store data in large clusters at Internet scale.
BookKeeper is able to handle large amounts of machines, held in several racks and and even datacenters, and BlobIt exploits all of the its magic features.
BlobIt is the data storage layer of EmailSuccess, a power full MTA (mail transfer agent) but it can be used by any Java application that needs a solution for distributed storage.
How it works ?
BlobIt stores Blobs (Binary Large Objects) on Bookies, a Bookie is the 'BookKeeper server' part.This picture show how it works
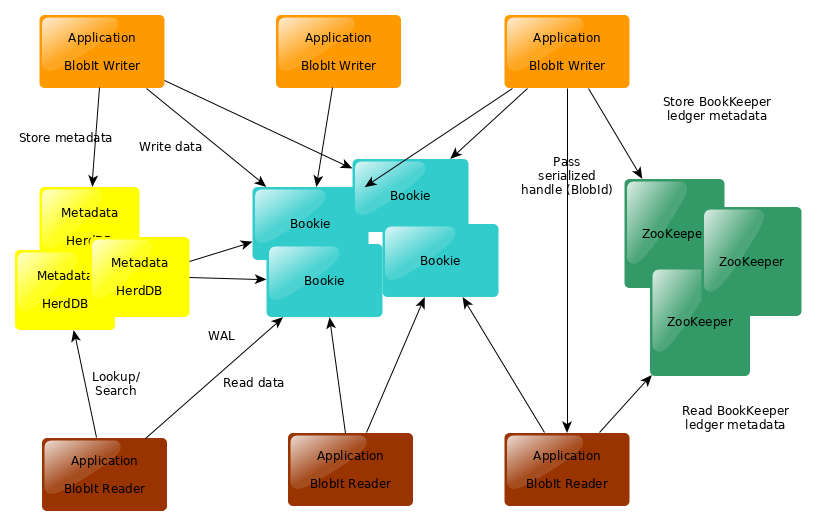
In BookKeeper data is organized in form of immutable streams of raw data named ledgers, each ledger is identified by a 64bit positive integer number.
BookKeeper does most of the hard work:
- replication
- consistency
- server discovery
- failure handling
- an efficient network protocol
- store data in very efficiently
- separate write path from the read path
- keep an in-memory read cache on the server in order to provide fast access to data that have written recently
- handle the ability to spread data across multiple disks per machine (both for journal and for data)
See BookKeeper documentation in order to understand better BookKeeper architecture, benefits and possible configurations.
BlobIt introduces a layer of abstraction of BookKeeper that makes: the client deals with Buckets which are partitions of the whole data space and Objects which are like the files in a traditional filesystem.
Each write returns an ObjectId which is a Smart ID which lets the reader access data by issuing network calls directly to the Bookies: the id itself contains all of the information needed to access data: ledger id, position, total size, number of parts.
So there is no "BlobIt server", the decentralized architecture of BookKeeper is fully exploited and there is no need to have a central server which proxies requests.
We also need a Metadata services, and currently we are using HerdDB which is in turn a Distributed Database also built upon Apache BookKeeper.
HerdDB architecture is fully decentralized, tables are grouped into tablespaces, each tablespace has one or more replicas and it is independent from the others.
HerdDB stores its white-ahead log on BookKeeper, and this way the write path of metadata flows thru bookies and leverages BookKeeper architecture.
BlobIt creates an HerdDB tablespace to store metadata for each bucket.
Usually you are going to co-locate the leader of the tablespace that holds metadata for a specific bucket nearby the clients that are writing data to that bucket and you will keep replicas on another rack (readers do not need the metadata service).
BookKeeper and HerdDB rely heavily on Apache ZooKeeper to store low level metadata and to implement service discovery.
Stay tuned !
We release this week the 0.2.0 version of BlobIt, the project is growing rapidly and we are going to implement a lot of new features soon.
If you use B2C-Commerce-Developer study material for exam, you will pass the exam for sure!
RispondiElimina